ot.datasets
Simple example datasets
Functions
- ot.datasets.make_1D_gauss(n, m, s)[source]
return a 1D histogram for a gaussian distribution (n bins, mean m and std s)
Examples using ot.datasets.make_1D_gauss

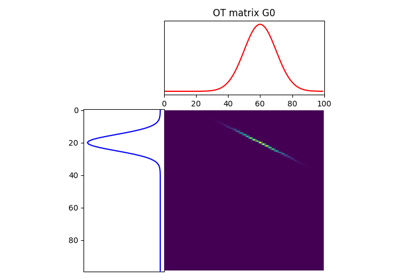
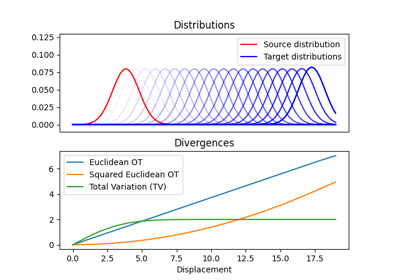
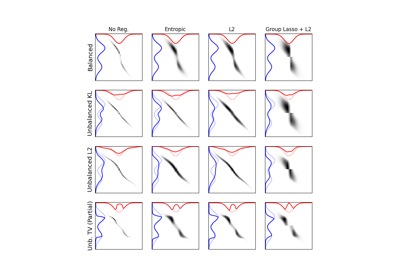
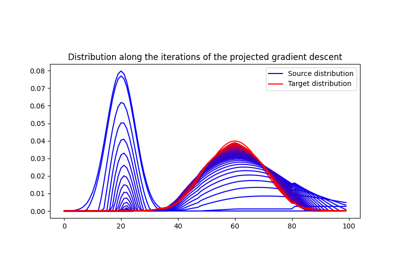
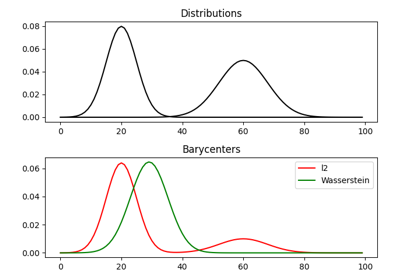

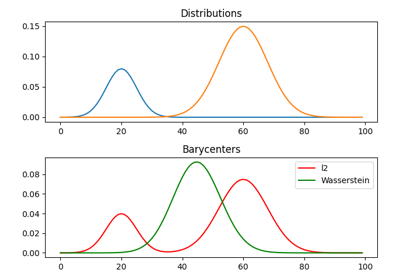
1D Wasserstein barycenter: exact LP vs entropic regularization
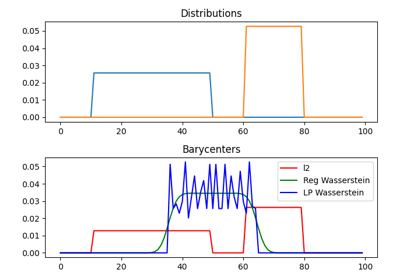
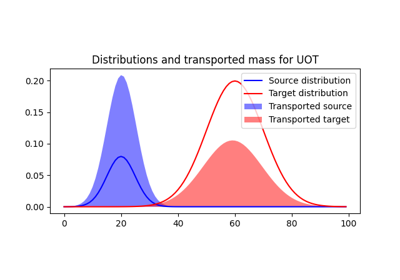
1D Wasserstein barycenter demo for Unbalanced distributions
- ot.datasets.make_2D_samples_gauss(n, m, sigma, random_state=None)[source]
Return n samples drawn from 2D gaussian \(\mathcal{N}(m, \sigma)\)
- Parameters:
n (int) – number of samples to make
m (ndarray, shape (2,)) – mean value of the gaussian distribution
sigma (ndarray, shape (2, 2)) – covariance matrix of the gaussian distribution
random_state (int, RandomState instance or None, optional (default=None)) – If int, random_state is the seed used by the random number generator; If RandomState instance, random_state is the random number generator; If None, the random number generator is the RandomState instance used by np.random.
- Returns:
X – n samples drawn from \(\mathcal{N}(m, \sigma)\).
- Return type:
ndarray, shape (n, 2)
Examples using ot.datasets.make_2D_samples_gauss
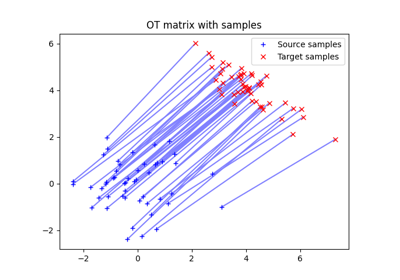
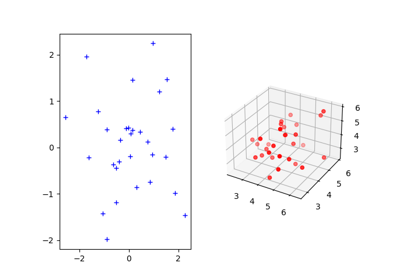
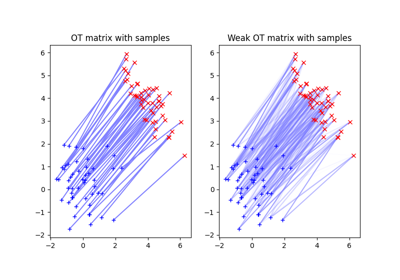
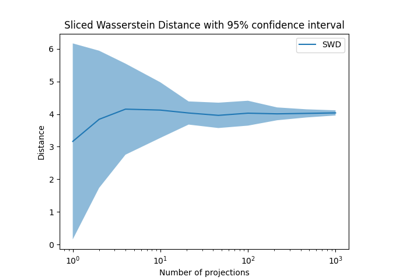
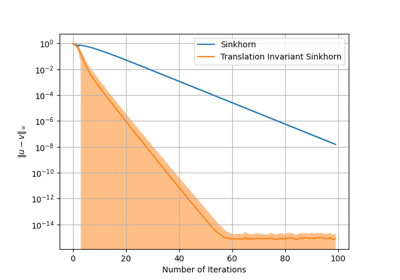
Translation Invariant Sinkhorn for Unbalanced Optimal Transport
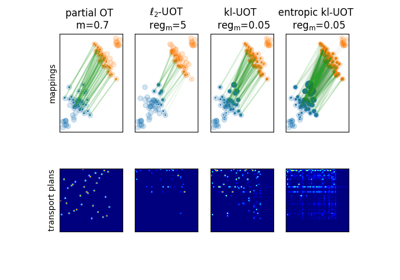
2D examples of exact and entropic unbalanced optimal transport
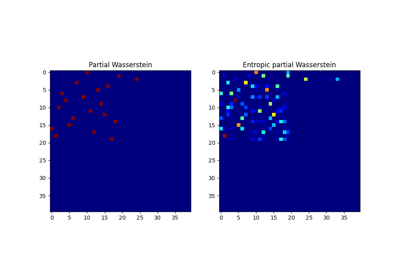
Partial Wasserstein and Gromov-Wasserstein example
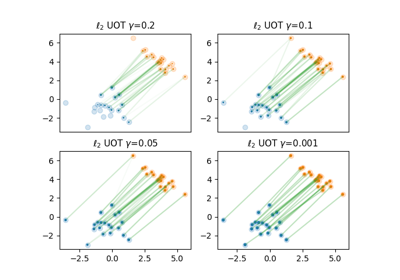
Regularization path of l2-penalized unbalanced optimal transport
- ot.datasets.make_data_classif(dataset, n, nz=0.5, theta=0, p=0.5, random_state=None, **kwargs)[source]
Dataset generation for classification problems
- Parameters:
dataset (str) – type of classification problem (see code)
n (int) – number of training samples
nz (float) – noise level (>0)
p (float) – proportion of one class in the binary setting
random_state (int, RandomState instance or None, optional (default=None)) – If int, random_state is the seed used by the random number generator; If RandomState instance, random_state is the random number generator; If None, the random number generator is the RandomState instance used by np.random.
- Returns:
X (ndarray, shape (n, d)) – n observation of size d
y (ndarray, shape (n,)) – labels of the samples.
Examples using ot.datasets.make_data_classif
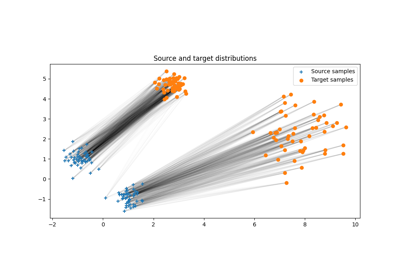
Dual OT solvers for entropic and quadratic regularized OT with Pytorch
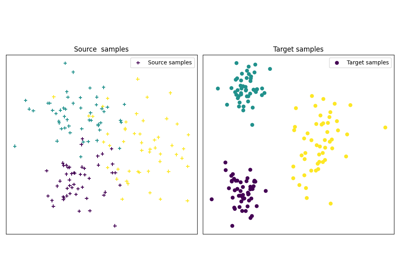
OT with Laplacian regularization for domain adaptation
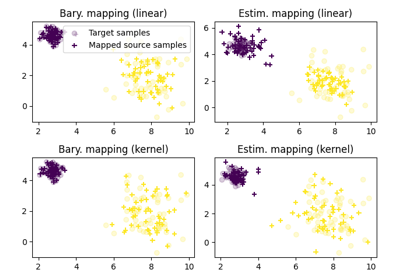
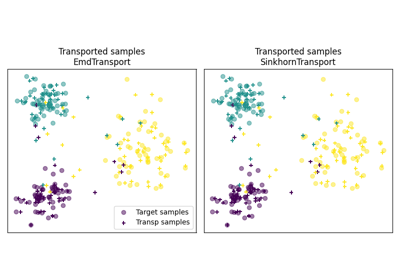
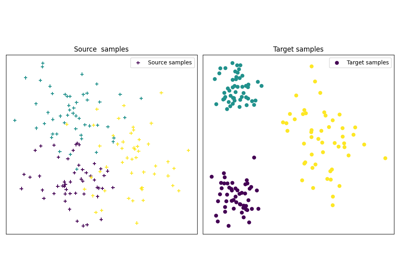
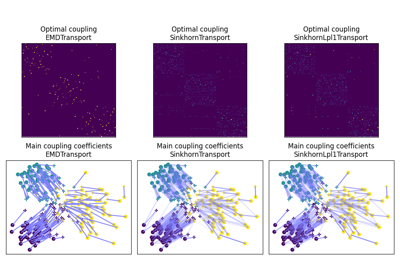
OT for domain adaptation on empirical distributions
- ot.datasets.make_gauss_hd(ns, nt, p=100, dim=5, m_diff=3.0, a=(10.0, 15.0), b=(3.0, 3.0), sub_the_same=False)[source]
Generation of source and target domains from Gaussian HD distributions
- Parameters:
ns (int) – number of samples (source)
nt (int) – number of samples (target)
p (int) – dimension of the ambient space the data live in
dim ((int,int) or int) – the intrinsic dimensions of the source and target Gaussian HD distriutions. If a single int the intrinsic dimension is assumed to be the same
m_diff (float) – the shift in the first coordinate of the means of the Gaussian HD distributions, i.e. ms_0 and mt_0, respectively (see code)
a ((float, float)) – positive floating numbers corresponding to the isotropic variances in the principal subspace, for the source and target distributions, respectively. The same as delta in [1], Proposition 2.2
b ((float, float)) – positive floating numbers corresponding to the isotropic variance outside the principal subspace for the source and target distributions, respectively.
sub_the_same (bool) – should the source/target Gaussian HD distributions live in the same principal subspace?
- Returns:
Xs (ndarray, shape (ns, p)) – ns observations of size p (source)
Xt (ndarray, shape (nt, p)) – nt observations of size p (destination)
pmts (list) – a list containing the parameters of the Gaussian HD distributions
.. _references-make_gauss_hd
References
- ot.datasets.make_1D_gauss(n, m, s)[source]
return a 1D histogram for a gaussian distribution (n bins, mean m and std s)
- ot.datasets.make_2D_samples_gauss(n, m, sigma, random_state=None)[source]
Return n samples drawn from 2D gaussian \(\mathcal{N}(m, \sigma)\)
- Parameters:
n (int) – number of samples to make
m (ndarray, shape (2,)) – mean value of the gaussian distribution
sigma (ndarray, shape (2, 2)) – covariance matrix of the gaussian distribution
random_state (int, RandomState instance or None, optional (default=None)) – If int, random_state is the seed used by the random number generator; If RandomState instance, random_state is the random number generator; If None, the random number generator is the RandomState instance used by np.random.
- Returns:
X – n samples drawn from \(\mathcal{N}(m, \sigma)\).
- Return type:
ndarray, shape (n, 2)
- ot.datasets.make_data_classif(dataset, n, nz=0.5, theta=0, p=0.5, random_state=None, **kwargs)[source]
Dataset generation for classification problems
- Parameters:
dataset (str) – type of classification problem (see code)
n (int) – number of training samples
nz (float) – noise level (>0)
p (float) – proportion of one class in the binary setting
random_state (int, RandomState instance or None, optional (default=None)) – If int, random_state is the seed used by the random number generator; If RandomState instance, random_state is the random number generator; If None, the random number generator is the RandomState instance used by np.random.
- Returns:
X (ndarray, shape (n, d)) – n observation of size d
y (ndarray, shape (n,)) – labels of the samples.
- ot.datasets.make_gauss_hd(ns, nt, p=100, dim=5, m_diff=3.0, a=(10.0, 15.0), b=(3.0, 3.0), sub_the_same=False)[source]
Generation of source and target domains from Gaussian HD distributions
- Parameters:
ns (int) – number of samples (source)
nt (int) – number of samples (target)
p (int) – dimension of the ambient space the data live in
dim ((int,int) or int) – the intrinsic dimensions of the source and target Gaussian HD distriutions. If a single int the intrinsic dimension is assumed to be the same
m_diff (float) – the shift in the first coordinate of the means of the Gaussian HD distributions, i.e. ms_0 and mt_0, respectively (see code)
a ((float, float)) – positive floating numbers corresponding to the isotropic variances in the principal subspace, for the source and target distributions, respectively. The same as delta in [1], Proposition 2.2
b ((float, float)) – positive floating numbers corresponding to the isotropic variance outside the principal subspace for the source and target distributions, respectively.
sub_the_same (bool) – should the source/target Gaussian HD distributions live in the same principal subspace?
- Returns:
Xs (ndarray, shape (ns, p)) – ns observations of size p (source)
Xt (ndarray, shape (nt, p)) – nt observations of size p (destination)
pmts (list) – a list containing the parameters of the Gaussian HD distributions
.. _references-make_gauss_hd
References