ot.smooth
Smooth and Sparse (KL an L2 reg.) and sparsity-constrained OT solvers.
Implementation of : Smooth and Sparse Optimal Transport. Mathieu Blondel, Vivien Seguy, Antoine Rolet. In Proc. of AISTATS 2018. https://arxiv.org/abs/1710.06276
(Original code from https://github.com/mblondel/smooth-ot/)
Sparsity-Constrained Optimal Transport. Liu, T., Puigcerver, J., & Blondel, M. (2023). Sparsity-constrained optimal transport. Proceedings of the Eleventh International Conference on Learning Representations (ICLR). https://arxiv.org/abs/2209.15466
[17] Blondel, M., Seguy, V., & Rolet, A. (2018). Smooth and Sparse Optimal Transport. Proceedings of the Twenty-First International Conference on Artificial Intelligence and Statistics (AISTATS).
[50] Liu, T., Puigcerver, J., & Blondel, M. (2023). Sparsity-constrained optimal transport. Proceedings of the Eleventh International Conference on Learning Representations (ICLR).
Functions
- ot.smooth.dual_obj_grad(alpha, beta, a, b, C, regul)[source]
Compute objective value and gradients of dual objective.
- Parameters:
alpha (array, shape = len(a))
beta (array, shape = len(b)) – Current iterate of dual potentials.
a (array, shape = len(a))
b (array, shape = len(b)) – Input histograms (should be non-negative and sum to 1).
C (array, shape = (len(a), len(b))) – Ground cost matrix.
regul (Regularization object) – Should implement a delta_Omega(X) method.
- Returns:
obj (float) – Objective value (higher is better).
grad_alpha (array, shape = len(a)) – Gradient w.r.t. alpha.
grad_beta (array, shape = len(b)) – Gradient w.r.t. beta.
- ot.smooth.get_plan_from_dual(alpha, beta, C, regul)[source]
Retrieve optimal transportation plan from optimal dual potentials.
- Parameters:
- Returns:
T – Optimal transportation plan.
- Return type:
array, shape = (len(a), len(b))
- ot.smooth.get_plan_from_semi_dual(alpha, b, C, regul)[source]
Retrieve optimal transportation plan from optimal semi-dual potentials.
- Parameters:
- Returns:
T – Optimal transportation plan.
- Return type:
array, shape = (len(a), len(b))
- ot.smooth.projection_simplex(V, z=1, axis=None)[source]
Projection of \(\mathbf{V}\) onto the simplex, scaled by z
\[\begin{split}P\left(\mathbf{V}, z\right) = \mathop{\arg \min}_{\substack{\mathbf{y} >= 0 \\ \sum_i \mathbf{y}_i = z}} \quad \|\mathbf{y} - \mathbf{V}\|^2\end{split}\]- Parameters:
V (ndarray, rank 2)
z (float or array) – If array, len(z) must be compatible with \(\mathbf{V}\)
axis (None or int) –
axis=None: project \(\mathbf{V}\) by \(P(\mathbf{V}.\mathrm{ravel}(), z)\)
axis=1: project each \(\mathbf{V}_i\) by \(P(\mathbf{V}_i, z_i)\)
axis=0: project each \(\mathbf{V}_{:, j}\) by \(P(\mathbf{V}_{:, j}, z_j)\)
- Returns:
projection
- Return type:
ndarray, shape \(\mathbf{V}\).shape
- ot.smooth.semi_dual_obj_grad(alpha, a, b, C, regul)[source]
Compute objective value and gradient of semi-dual objective.
- Parameters:
alpha (array, shape = len(a)) – Current iterate of semi-dual potentials.
a (array, shape = len(a))
b (array, shape = len(b)) – Input histograms (should be non-negative and sum to 1).
C (array, shape = (len(a), len(b))) – Ground cost matrix.
regul (Regularization object) – Should implement a max_Omega(X) method.
- Returns:
obj (float) – Objective value (higher is better).
grad (array, shape = len(a)) – Gradient w.r.t. alpha.
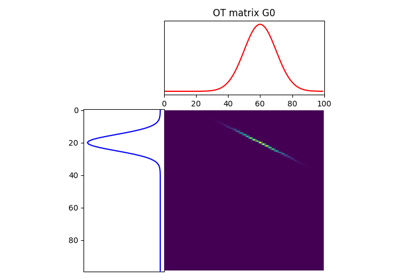
- ot.smooth.smooth_ot_dual(a, b, M, reg, reg_type='l2', method='L-BFGS-B', stopThr=1e-09, numItermax=500, verbose=False, log=False, max_nz=None)[source]
Solve the regularized OT problem in the dual and return the OT matrix
The function solves the smooth relaxed dual formulation (7) in [17]:
\[\max_{\alpha,\beta}\quad \mathbf{a}^T\alpha + \mathbf{b}^T\beta - \sum_j \delta_\Omega \left(\alpha+\beta_j-\mathbf{m}_j \right)\]where :
\(\mathbf{m}_j\) is the j-th column of the cost matrix
\(\delta_\Omega\) is the convex conjugate of the regularization term \(\Omega\)
\(\mathbf{a}\) and \(\mathbf{b}\) are source and target weights (sum to 1)
The OT matrix can is reconstructed from the gradient of \(\delta_\Omega\) (See [17] Proposition 1). The optimization algorithm is using gradient decent (L-BFGS by default).
- Parameters:
a (np.ndarray (ns,)) – samples weights in the source domain
b (np.ndarray (nt,) or np.ndarray (nt,nbb)) – samples in the target domain, compute sinkhorn with multiple targets and fixed \(\mathbf{M}\) if \(\mathbf{b}\) is a matrix (return OT loss + dual variables in log)
M (np.ndarray (ns,nt)) – loss matrix
reg (float) – Regularization term >0
reg_type (str) –
Regularization type, can be the following (default =’l2’):
’kl’ : Kullback Leibler (~ Neg-entropy used in sinkhorn [2])
’l2’ : Squared Euclidean regularization
’sparsity_constrained’ : Sparsity-constrained regularization [50]
max_nz (int or None, optional. Used only in the case of reg_type = 'sparsity_constrained' to specify the maximum number of nonzeros per column of the optimal plan;) – not used for other regularization types.
method (str) – Solver to use for scipy.optimize.minimize
numItermax (int, optional) – Max number of iterations
stopThr (float, optional) – Stop threshold on error (>0)
verbose (bool, optional) – Print information along iterations
log (bool, optional) – record log if True
- Returns:
gamma ((ns, nt) ndarray) – Optimal transportation matrix for the given parameters
log (dict) – log dictionary return only if log==True in parameters
References
See also
ot.lp.emdUnregularized OT
ot.sinhornEntropic regularized OT
ot.optim.cgGeneral regularized OT
Examples using ot.smooth.smooth_ot_dual
- ot.smooth.smooth_ot_semi_dual(a, b, M, reg, reg_type='l2', max_nz=None, method='L-BFGS-B', stopThr=1e-09, numItermax=500, verbose=False, log=False)[source]
Solve the regularized OT problem in the semi-dual and return the OT matrix
The function solves the smooth relaxed dual formulation (10) in [17]:
\[\max_{\alpha}\quad \mathbf{a}^T\alpha- \mathrm{OT}_\Omega^*(\alpha, \mathbf{b})\]where :
\[\mathrm{OT}_\Omega^*(\alpha,b)=\sum_j \mathbf{b}_j\]\(\mathbf{m}_j\) is the j-th column of the cost matrix
\(\mathrm{OT}_\Omega^*(\alpha,b)\) is defined in Eq. (9) in [17]
\(\mathbf{a}\) and \(\mathbf{b}\) are source and target weights (sum to 1)
The OT matrix can is reconstructed using [17] Proposition 2. The optimization algorithm is using gradient decent (L-BFGS by default).
- Parameters:
a (np.ndarray (ns,)) – samples weights in the source domain
b (np.ndarray (nt,) or np.ndarray (nt,nbb)) – samples in the target domain, compute sinkhorn with multiple targets and fixed:math:mathbf{M} if \(\mathbf{b}\) is a matrix (return OT loss + dual variables in log)
M (np.ndarray (ns,nt)) – loss matrix
reg (float) – Regularization term >0
reg_type (str) –
Regularization type, can be the following (default =’l2’):
’kl’ : Kullback Leibler (~ Neg-entropy used in sinkhorn [2])
’l2’ : Squared Euclidean regularization
’sparsity_constrained’ : Sparsity-constrained regularization [50]
max_nz (int or None, optional. Used only in the case of reg_type = 'sparsity_constrained' to specify the maximum number of nonzeros per column of the optimal plan;) – not used for other regularization types.
method (str) – Solver to use for scipy.optimize.minimize
numItermax (int, optional) – Max number of iterations
stopThr (float, optional) – Stop threshold on error (>0)
verbose (bool, optional) – Print information along iterations
log (bool, optional) – record log if True
- Returns:
gamma ((ns, nt) ndarray) – Optimal transportation matrix for the given parameters
log (dict) – log dictionary return only if log==True in parameters
References
See also
ot.lp.emdUnregularized OT
ot.sinhornEntropic regularized OT
ot.optim.cgGeneral regularized OT
- ot.smooth.solve_dual(a, b, C, regul, method='L-BFGS-B', tol=0.001, max_iter=500, verbose=False)[source]
Solve the “smoothed” dual objective.
- Parameters:
a (array, shape = (len(a), ))
b (array, shape = (len(b), )) – Input histograms (should be non-negative and sum to 1).
C (array, shape = (len(a), len(b))) – Ground cost matrix.
regul (Regularization object) – Should implement a delta_Omega(X) method.
method (str) – Solver to be used (passed to scipy.optimize.minimize).
tol (float) – Tolerance parameter.
max_iter (int) – Maximum number of iterations.
- Returns:
alpha (array, shape = (len(a), ))
beta (array, shape = (len(b), )) – Dual potentials.
- ot.smooth.solve_semi_dual(a, b, C, regul, method='L-BFGS-B', tol=0.001, max_iter=500, verbose=False)[source]
Solve the “smoothed” semi-dual objective.
- Parameters:
a (array, shape = (len(a), ))
b (array, shape = (len(b), )) – Input histograms (should be non-negative and sum to 1).
C (array, shape = (len(a), len(b))) – Ground cost matrix.
regul (Regularization object) – Should implement a max_Omega(X) method.
method (str) – Solver to be used (passed to scipy.optimize.minimize).
tol (float) – Tolerance parameter.
max_iter (int) – Maximum number of iterations.
- Returns:
alpha – Semi-dual potentials.
- Return type:
array, shape = (len(a), )
Classes
- class ot.smooth.NegEntropy(gamma=1.0)[source]
NegEntropy regularization
- delta_Omega(X)[source]
Compute \(\delta_\Omega(\mathbf{X}_{:, j})\) for each \(\mathbf{X}_{:, j}\).
\[\delta_\Omega(\mathbf{x}) = \sup_{\mathbf{y} >= 0} \ \mathbf{y}^T \mathbf{x} - \Omega(\mathbf{y})\]- Parameters:
X (array, shape = (len(a), len(b))) – Input array.
- Returns:
v (array, (len(b), )) – Values: \(\mathbf{v}_j = \delta_\Omega(\mathbf{X}_{:, j})\)
G (array, (len(a), len(b))) – Gradients: \(\mathbf{G}_{:, j} = \nabla \delta_\Omega(\mathbf{X}_{:, j})\)
- max_Omega(X, b)[source]
Compute \(\mathrm{max}_{\Omega, j}(\mathbf{X}_{:, j})\) for each \(\mathbf{X}_{:, j}\).
\[\mathrm{max}_{\Omega, j}(\mathbf{x}) = \sup_{\substack{\mathbf{y} >= 0 \ \sum_i \mathbf{y}_i = 1}} \mathbf{y}^T \mathbf{x} - \frac{1}{\mathbf{b}_j} \Omega(\mathbf{b}_j \mathbf{y})\]- Parameters:
- Returns:
v (array, (len(b), )) – Values: \(\mathbf{v}_j = \mathrm{max}_{\Omega, j}(\mathbf{X}_{:, j})\)
G (array, (len(a), len(b))) – Gradients: \(\mathbf{G}_{:, j} = \nabla \mathrm{max}_{\Omega, j}(\mathbf{X}_{:, j})\)
- class ot.smooth.Regularization(gamma=1.0)[source]
Base class for Regularization objects
Notes
This class is not intended for direct use but as apparent for true regularization implementation.
- delta_Omega()[source]
Compute \(\delta_\Omega(\mathbf{X}_{:, j})\) for each \(\mathbf{X}_{:, j}\).
\[\delta_\Omega(\mathbf{x}) = \sup_{\mathbf{y} >= 0} \ \mathbf{y}^T \mathbf{x} - \Omega(\mathbf{y})\]- Parameters:
X (array, shape = (len(a), len(b))) – Input array.
- Returns:
v (array, (len(b), )) – Values: \(\mathbf{v}_j = \delta_\Omega(\mathbf{X}_{:, j})\)
G (array, (len(a), len(b))) – Gradients: \(\mathbf{G}_{:, j} = \nabla \delta_\Omega(\mathbf{X}_{:, j})\)
- max_Omega(b)[source]
Compute \(\mathrm{max}_{\Omega, j}(\mathbf{X}_{:, j})\) for each \(\mathbf{X}_{:, j}\).
\[\mathrm{max}_{\Omega, j}(\mathbf{x}) = \sup_{\substack{\mathbf{y} >= 0 \ \sum_i \mathbf{y}_i = 1}} \mathbf{y}^T \mathbf{x} - \frac{1}{\mathbf{b}_j} \Omega(\mathbf{b}_j \mathbf{y})\]- Parameters:
- Returns:
v (array, (len(b), )) – Values: \(\mathbf{v}_j = \mathrm{max}_{\Omega, j}(\mathbf{X}_{:, j})\)
G (array, (len(a), len(b))) – Gradients: \(\mathbf{G}_{:, j} = \nabla \mathrm{max}_{\Omega, j}(\mathbf{X}_{:, j})\)
- class ot.smooth.SparsityConstrained(max_nz, gamma=1.0)[source]
Squared L2 regularization with sparsity constraints
- delta_Omega(X)[source]
Compute \(\delta_\Omega(\mathbf{X}_{:, j})\) for each \(\mathbf{X}_{:, j}\).
\[\delta_\Omega(\mathbf{x}) = \sup_{\mathbf{y} >= 0} \ \mathbf{y}^T \mathbf{x} - \Omega(\mathbf{y})\]- Parameters:
X (array, shape = (len(a), len(b))) – Input array.
- Returns:
v (array, (len(b), )) – Values: \(\mathbf{v}_j = \delta_\Omega(\mathbf{X}_{:, j})\)
G (array, (len(a), len(b))) – Gradients: \(\mathbf{G}_{:, j} = \nabla \delta_\Omega(\mathbf{X}_{:, j})\)
- max_Omega(X, b)[source]
Compute \(\mathrm{max}_{\Omega, j}(\mathbf{X}_{:, j})\) for each \(\mathbf{X}_{:, j}\).
\[\mathrm{max}_{\Omega, j}(\mathbf{x}) = \sup_{\substack{\mathbf{y} >= 0 \ \sum_i \mathbf{y}_i = 1}} \mathbf{y}^T \mathbf{x} - \frac{1}{\mathbf{b}_j} \Omega(\mathbf{b}_j \mathbf{y})\]- Parameters:
- Returns:
v (array, (len(b), )) – Values: \(\mathbf{v}_j = \mathrm{max}_{\Omega, j}(\mathbf{X}_{:, j})\)
G (array, (len(a), len(b))) – Gradients: \(\mathbf{G}_{:, j} = \nabla \mathrm{max}_{\Omega, j}(\mathbf{X}_{:, j})\)
- class ot.smooth.SquaredL2(gamma=1.0)[source]
Squared L2 regularization
- delta_Omega(X)[source]
Compute \(\delta_\Omega(\mathbf{X}_{:, j})\) for each \(\mathbf{X}_{:, j}\).
\[\delta_\Omega(\mathbf{x}) = \sup_{\mathbf{y} >= 0} \ \mathbf{y}^T \mathbf{x} - \Omega(\mathbf{y})\]- Parameters:
X (array, shape = (len(a), len(b))) – Input array.
- Returns:
v (array, (len(b), )) – Values: \(\mathbf{v}_j = \delta_\Omega(\mathbf{X}_{:, j})\)
G (array, (len(a), len(b))) – Gradients: \(\mathbf{G}_{:, j} = \nabla \delta_\Omega(\mathbf{X}_{:, j})\)
- max_Omega(X, b)[source]
Compute \(\mathrm{max}_{\Omega, j}(\mathbf{X}_{:, j})\) for each \(\mathbf{X}_{:, j}\).
\[\mathrm{max}_{\Omega, j}(\mathbf{x}) = \sup_{\substack{\mathbf{y} >= 0 \ \sum_i \mathbf{y}_i = 1}} \mathbf{y}^T \mathbf{x} - \frac{1}{\mathbf{b}_j} \Omega(\mathbf{b}_j \mathbf{y})\]- Parameters:
- Returns:
v (array, (len(b), )) – Values: \(\mathbf{v}_j = \mathrm{max}_{\Omega, j}(\mathbf{X}_{:, j})\)
G (array, (len(a), len(b))) – Gradients: \(\mathbf{G}_{:, j} = \nabla \mathrm{max}_{\Omega, j}(\mathbf{X}_{:, j})\)
- class ot.smooth.NegEntropy(gamma=1.0)[source]
NegEntropy regularization
- delta_Omega(X)[source]
Compute \(\delta_\Omega(\mathbf{X}_{:, j})\) for each \(\mathbf{X}_{:, j}\).
\[\delta_\Omega(\mathbf{x}) = \sup_{\mathbf{y} >= 0} \ \mathbf{y}^T \mathbf{x} - \Omega(\mathbf{y})\]- Parameters:
X (array, shape = (len(a), len(b))) – Input array.
- Returns:
v (array, (len(b), )) – Values: \(\mathbf{v}_j = \delta_\Omega(\mathbf{X}_{:, j})\)
G (array, (len(a), len(b))) – Gradients: \(\mathbf{G}_{:, j} = \nabla \delta_\Omega(\mathbf{X}_{:, j})\)
- max_Omega(X, b)[source]
Compute \(\mathrm{max}_{\Omega, j}(\mathbf{X}_{:, j})\) for each \(\mathbf{X}_{:, j}\).
\[\mathrm{max}_{\Omega, j}(\mathbf{x}) = \sup_{\substack{\mathbf{y} >= 0 \ \sum_i \mathbf{y}_i = 1}} \mathbf{y}^T \mathbf{x} - \frac{1}{\mathbf{b}_j} \Omega(\mathbf{b}_j \mathbf{y})\]- Parameters:
- Returns:
v (array, (len(b), )) – Values: \(\mathbf{v}_j = \mathrm{max}_{\Omega, j}(\mathbf{X}_{:, j})\)
G (array, (len(a), len(b))) – Gradients: \(\mathbf{G}_{:, j} = \nabla \mathrm{max}_{\Omega, j}(\mathbf{X}_{:, j})\)
- class ot.smooth.Regularization(gamma=1.0)[source]
Base class for Regularization objects
Notes
This class is not intended for direct use but as apparent for true regularization implementation.
- delta_Omega()[source]
Compute \(\delta_\Omega(\mathbf{X}_{:, j})\) for each \(\mathbf{X}_{:, j}\).
\[\delta_\Omega(\mathbf{x}) = \sup_{\mathbf{y} >= 0} \ \mathbf{y}^T \mathbf{x} - \Omega(\mathbf{y})\]- Parameters:
X (array, shape = (len(a), len(b))) – Input array.
- Returns:
v (array, (len(b), )) – Values: \(\mathbf{v}_j = \delta_\Omega(\mathbf{X}_{:, j})\)
G (array, (len(a), len(b))) – Gradients: \(\mathbf{G}_{:, j} = \nabla \delta_\Omega(\mathbf{X}_{:, j})\)
- max_Omega(b)[source]
Compute \(\mathrm{max}_{\Omega, j}(\mathbf{X}_{:, j})\) for each \(\mathbf{X}_{:, j}\).
\[\mathrm{max}_{\Omega, j}(\mathbf{x}) = \sup_{\substack{\mathbf{y} >= 0 \ \sum_i \mathbf{y}_i = 1}} \mathbf{y}^T \mathbf{x} - \frac{1}{\mathbf{b}_j} \Omega(\mathbf{b}_j \mathbf{y})\]- Parameters:
- Returns:
v (array, (len(b), )) – Values: \(\mathbf{v}_j = \mathrm{max}_{\Omega, j}(\mathbf{X}_{:, j})\)
G (array, (len(a), len(b))) – Gradients: \(\mathbf{G}_{:, j} = \nabla \mathrm{max}_{\Omega, j}(\mathbf{X}_{:, j})\)
- class ot.smooth.SparsityConstrained(max_nz, gamma=1.0)[source]
Squared L2 regularization with sparsity constraints
- delta_Omega(X)[source]
Compute \(\delta_\Omega(\mathbf{X}_{:, j})\) for each \(\mathbf{X}_{:, j}\).
\[\delta_\Omega(\mathbf{x}) = \sup_{\mathbf{y} >= 0} \ \mathbf{y}^T \mathbf{x} - \Omega(\mathbf{y})\]- Parameters:
X (array, shape = (len(a), len(b))) – Input array.
- Returns:
v (array, (len(b), )) – Values: \(\mathbf{v}_j = \delta_\Omega(\mathbf{X}_{:, j})\)
G (array, (len(a), len(b))) – Gradients: \(\mathbf{G}_{:, j} = \nabla \delta_\Omega(\mathbf{X}_{:, j})\)
- max_Omega(X, b)[source]
Compute \(\mathrm{max}_{\Omega, j}(\mathbf{X}_{:, j})\) for each \(\mathbf{X}_{:, j}\).
\[\mathrm{max}_{\Omega, j}(\mathbf{x}) = \sup_{\substack{\mathbf{y} >= 0 \ \sum_i \mathbf{y}_i = 1}} \mathbf{y}^T \mathbf{x} - \frac{1}{\mathbf{b}_j} \Omega(\mathbf{b}_j \mathbf{y})\]- Parameters:
- Returns:
v (array, (len(b), )) – Values: \(\mathbf{v}_j = \mathrm{max}_{\Omega, j}(\mathbf{X}_{:, j})\)
G (array, (len(a), len(b))) – Gradients: \(\mathbf{G}_{:, j} = \nabla \mathrm{max}_{\Omega, j}(\mathbf{X}_{:, j})\)
- class ot.smooth.SquaredL2(gamma=1.0)[source]
Squared L2 regularization
- delta_Omega(X)[source]
Compute \(\delta_\Omega(\mathbf{X}_{:, j})\) for each \(\mathbf{X}_{:, j}\).
\[\delta_\Omega(\mathbf{x}) = \sup_{\mathbf{y} >= 0} \ \mathbf{y}^T \mathbf{x} - \Omega(\mathbf{y})\]- Parameters:
X (array, shape = (len(a), len(b))) – Input array.
- Returns:
v (array, (len(b), )) – Values: \(\mathbf{v}_j = \delta_\Omega(\mathbf{X}_{:, j})\)
G (array, (len(a), len(b))) – Gradients: \(\mathbf{G}_{:, j} = \nabla \delta_\Omega(\mathbf{X}_{:, j})\)
- max_Omega(X, b)[source]
Compute \(\mathrm{max}_{\Omega, j}(\mathbf{X}_{:, j})\) for each \(\mathbf{X}_{:, j}\).
\[\mathrm{max}_{\Omega, j}(\mathbf{x}) = \sup_{\substack{\mathbf{y} >= 0 \ \sum_i \mathbf{y}_i = 1}} \mathbf{y}^T \mathbf{x} - \frac{1}{\mathbf{b}_j} \Omega(\mathbf{b}_j \mathbf{y})\]- Parameters:
- Returns:
v (array, (len(b), )) – Values: \(\mathbf{v}_j = \mathrm{max}_{\Omega, j}(\mathbf{X}_{:, j})\)
G (array, (len(a), len(b))) – Gradients: \(\mathbf{G}_{:, j} = \nabla \mathrm{max}_{\Omega, j}(\mathbf{X}_{:, j})\)
- ot.smooth.dual_obj_grad(alpha, beta, a, b, C, regul)[source]
Compute objective value and gradients of dual objective.
- Parameters:
alpha (array, shape = len(a))
beta (array, shape = len(b)) – Current iterate of dual potentials.
a (array, shape = len(a))
b (array, shape = len(b)) – Input histograms (should be non-negative and sum to 1).
C (array, shape = (len(a), len(b))) – Ground cost matrix.
regul (Regularization object) – Should implement a delta_Omega(X) method.
- Returns:
obj (float) – Objective value (higher is better).
grad_alpha (array, shape = len(a)) – Gradient w.r.t. alpha.
grad_beta (array, shape = len(b)) – Gradient w.r.t. beta.
- ot.smooth.get_plan_from_dual(alpha, beta, C, regul)[source]
Retrieve optimal transportation plan from optimal dual potentials.
- Parameters:
- Returns:
T – Optimal transportation plan.
- Return type:
array, shape = (len(a), len(b))
- ot.smooth.get_plan_from_semi_dual(alpha, b, C, regul)[source]
Retrieve optimal transportation plan from optimal semi-dual potentials.
- Parameters:
- Returns:
T – Optimal transportation plan.
- Return type:
array, shape = (len(a), len(b))
- ot.smooth.projection_simplex(V, z=1, axis=None)[source]
Projection of \(\mathbf{V}\) onto the simplex, scaled by z
\[\begin{split}P\left(\mathbf{V}, z\right) = \mathop{\arg \min}_{\substack{\mathbf{y} >= 0 \\ \sum_i \mathbf{y}_i = z}} \quad \|\mathbf{y} - \mathbf{V}\|^2\end{split}\]- Parameters:
V (ndarray, rank 2)
z (float or array) – If array, len(z) must be compatible with \(\mathbf{V}\)
axis (None or int) –
axis=None: project \(\mathbf{V}\) by \(P(\mathbf{V}.\mathrm{ravel}(), z)\)
axis=1: project each \(\mathbf{V}_i\) by \(P(\mathbf{V}_i, z_i)\)
axis=0: project each \(\mathbf{V}_{:, j}\) by \(P(\mathbf{V}_{:, j}, z_j)\)
- Returns:
projection
- Return type:
ndarray, shape \(\mathbf{V}\).shape
- ot.smooth.semi_dual_obj_grad(alpha, a, b, C, regul)[source]
Compute objective value and gradient of semi-dual objective.
- Parameters:
alpha (array, shape = len(a)) – Current iterate of semi-dual potentials.
a (array, shape = len(a))
b (array, shape = len(b)) – Input histograms (should be non-negative and sum to 1).
C (array, shape = (len(a), len(b))) – Ground cost matrix.
regul (Regularization object) – Should implement a max_Omega(X) method.
- Returns:
obj (float) – Objective value (higher is better).
grad (array, shape = len(a)) – Gradient w.r.t. alpha.
- ot.smooth.smooth_ot_dual(a, b, M, reg, reg_type='l2', method='L-BFGS-B', stopThr=1e-09, numItermax=500, verbose=False, log=False, max_nz=None)[source]
Solve the regularized OT problem in the dual and return the OT matrix
The function solves the smooth relaxed dual formulation (7) in [17]:
\[\max_{\alpha,\beta}\quad \mathbf{a}^T\alpha + \mathbf{b}^T\beta - \sum_j \delta_\Omega \left(\alpha+\beta_j-\mathbf{m}_j \right)\]where :
\(\mathbf{m}_j\) is the j-th column of the cost matrix
\(\delta_\Omega\) is the convex conjugate of the regularization term \(\Omega\)
\(\mathbf{a}\) and \(\mathbf{b}\) are source and target weights (sum to 1)
The OT matrix can is reconstructed from the gradient of \(\delta_\Omega\) (See [17] Proposition 1). The optimization algorithm is using gradient decent (L-BFGS by default).
- Parameters:
a (np.ndarray (ns,)) – samples weights in the source domain
b (np.ndarray (nt,) or np.ndarray (nt,nbb)) – samples in the target domain, compute sinkhorn with multiple targets and fixed \(\mathbf{M}\) if \(\mathbf{b}\) is a matrix (return OT loss + dual variables in log)
M (np.ndarray (ns,nt)) – loss matrix
reg (float) – Regularization term >0
reg_type (str) –
Regularization type, can be the following (default =’l2’):
’kl’ : Kullback Leibler (~ Neg-entropy used in sinkhorn [2])
’l2’ : Squared Euclidean regularization
’sparsity_constrained’ : Sparsity-constrained regularization [50]
max_nz (int or None, optional. Used only in the case of reg_type = 'sparsity_constrained' to specify the maximum number of nonzeros per column of the optimal plan;) – not used for other regularization types.
method (str) – Solver to use for scipy.optimize.minimize
numItermax (int, optional) – Max number of iterations
stopThr (float, optional) – Stop threshold on error (>0)
verbose (bool, optional) – Print information along iterations
log (bool, optional) – record log if True
- Returns:
gamma ((ns, nt) ndarray) – Optimal transportation matrix for the given parameters
log (dict) – log dictionary return only if log==True in parameters
References
See also
ot.lp.emdUnregularized OT
ot.sinhornEntropic regularized OT
ot.optim.cgGeneral regularized OT
- ot.smooth.smooth_ot_semi_dual(a, b, M, reg, reg_type='l2', max_nz=None, method='L-BFGS-B', stopThr=1e-09, numItermax=500, verbose=False, log=False)[source]
Solve the regularized OT problem in the semi-dual and return the OT matrix
The function solves the smooth relaxed dual formulation (10) in [17]:
\[\max_{\alpha}\quad \mathbf{a}^T\alpha- \mathrm{OT}_\Omega^*(\alpha, \mathbf{b})\]where :
\[\mathrm{OT}_\Omega^*(\alpha,b)=\sum_j \mathbf{b}_j\]\(\mathbf{m}_j\) is the j-th column of the cost matrix
\(\mathrm{OT}_\Omega^*(\alpha,b)\) is defined in Eq. (9) in [17]
\(\mathbf{a}\) and \(\mathbf{b}\) are source and target weights (sum to 1)
The OT matrix can is reconstructed using [17] Proposition 2. The optimization algorithm is using gradient decent (L-BFGS by default).
- Parameters:
a (np.ndarray (ns,)) – samples weights in the source domain
b (np.ndarray (nt,) or np.ndarray (nt,nbb)) – samples in the target domain, compute sinkhorn with multiple targets and fixed:math:mathbf{M} if \(\mathbf{b}\) is a matrix (return OT loss + dual variables in log)
M (np.ndarray (ns,nt)) – loss matrix
reg (float) – Regularization term >0
reg_type (str) –
Regularization type, can be the following (default =’l2’):
’kl’ : Kullback Leibler (~ Neg-entropy used in sinkhorn [2])
’l2’ : Squared Euclidean regularization
’sparsity_constrained’ : Sparsity-constrained regularization [50]
max_nz (int or None, optional. Used only in the case of reg_type = 'sparsity_constrained' to specify the maximum number of nonzeros per column of the optimal plan;) – not used for other regularization types.
method (str) – Solver to use for scipy.optimize.minimize
numItermax (int, optional) – Max number of iterations
stopThr (float, optional) – Stop threshold on error (>0)
verbose (bool, optional) – Print information along iterations
log (bool, optional) – record log if True
- Returns:
gamma ((ns, nt) ndarray) – Optimal transportation matrix for the given parameters
log (dict) – log dictionary return only if log==True in parameters
References
See also
ot.lp.emdUnregularized OT
ot.sinhornEntropic regularized OT
ot.optim.cgGeneral regularized OT
- ot.smooth.solve_dual(a, b, C, regul, method='L-BFGS-B', tol=0.001, max_iter=500, verbose=False)[source]
Solve the “smoothed” dual objective.
- Parameters:
a (array, shape = (len(a), ))
b (array, shape = (len(b), )) – Input histograms (should be non-negative and sum to 1).
C (array, shape = (len(a), len(b))) – Ground cost matrix.
regul (Regularization object) – Should implement a delta_Omega(X) method.
method (str) – Solver to be used (passed to scipy.optimize.minimize).
tol (float) – Tolerance parameter.
max_iter (int) – Maximum number of iterations.
- Returns:
alpha (array, shape = (len(a), ))
beta (array, shape = (len(b), )) – Dual potentials.
- ot.smooth.solve_semi_dual(a, b, C, regul, method='L-BFGS-B', tol=0.001, max_iter=500, verbose=False)[source]
Solve the “smoothed” semi-dual objective.
- Parameters:
a (array, shape = (len(a), ))
b (array, shape = (len(b), )) – Input histograms (should be non-negative and sum to 1).
C (array, shape = (len(a), len(b))) – Ground cost matrix.
regul (Regularization object) – Should implement a max_Omega(X) method.
method (str) – Solver to be used (passed to scipy.optimize.minimize).
tol (float) – Tolerance parameter.
max_iter (int) – Maximum number of iterations.
- Returns:
alpha – Semi-dual potentials.
- Return type:
array, shape = (len(a), )