Note
Go to the end to download the full example code.
Comparison of Fused Gromov-Wasserstein solvers
Note
Example added in release: 0.9.1.
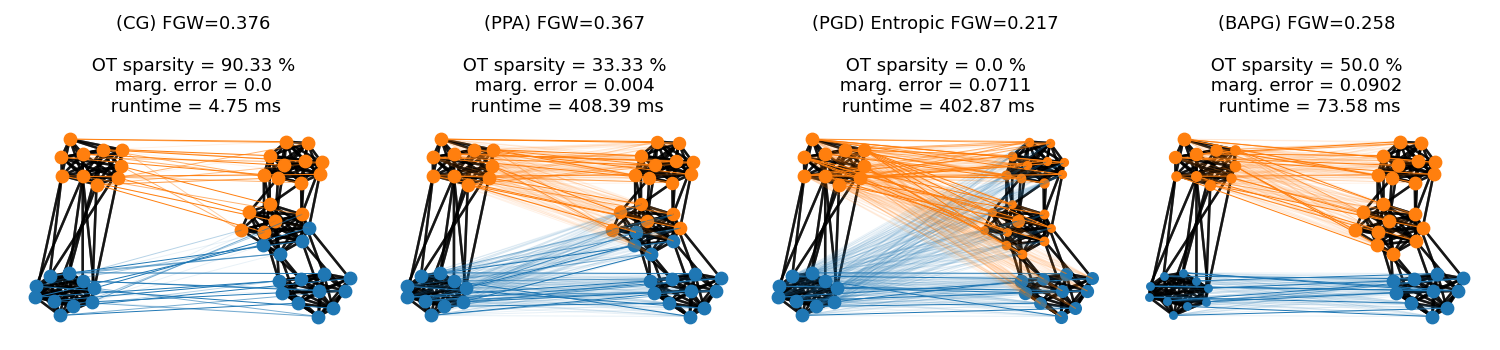
This example illustrates the computation of FGW for attributed graphs using 4 different solvers to estimate the distance based on Conditional Gradient [24], Sinkhorn projections [12, 51] and alternated Bregman projections [63, 64].
We generate two graphs following Stochastic Block Models further endowed with node features and compute their FGW matchings.
[12] Gabriel Peyré, Marco Cuturi, and Justin Solomon (2016), “Gromov-Wasserstein averaging of kernel and distance matrices”. International Conference on Machine Learning (ICML).
[24] Vayer Titouan, Chapel Laetitia, Flamary Rémi, Tavenard Romain and Courty Nicolas “Optimal Transport for structured data with application on graphs” International Conference on Machine Learning (ICML). 2019.
[51] Xu, H., Luo, D., Zha, H., & Carin, L. (2019). “Gromov-wasserstein learning for graph matching and node embedding”. In International Conference on Machine Learning (ICML), 2019.
[63] Li, J., Tang, J., Kong, L., Liu, H., Li, J., So, A. M. C., & Blanchet, J. “A Convergent Single-Loop Algorithm for Relaxation of Gromov-Wasserstein in Graph Data”. International Conference on Learning Representations (ICLR), 2023.
[64] Ma, X., Chu, X., Wang, Y., Lin, Y., Zhao, J., Ma, L., & Zhu, W. “Fused Gromov-Wasserstein Graph Mixup for Graph-level Classifications”. In Thirty-seventh Conference on Neural Information Processing Systems (NeurIPS), 2023.
# Author: Cédric Vincent-Cuaz <cedvincentcuaz@gmail.com>
#
# License: MIT License
# sphinx_gallery_thumbnail_number = 1
import numpy as np
import matplotlib.pylab as pl
from ot.gromov import (
fused_gromov_wasserstein,
entropic_fused_gromov_wasserstein,
BAPG_fused_gromov_wasserstein,
)
import networkx
from networkx.generators.community import stochastic_block_model as sbm
from time import time
Generate two graphs following Stochastic Block models of 2 and 3 clusters.
np.random.seed(0)
N2 = 20 # 2 communities
N3 = 30 # 3 communities
p2 = [[1.0, 0.1], [0.1, 0.9]]
p3 = [[1.0, 0.1, 0.0], [0.1, 0.95, 0.1], [0.0, 0.1, 0.9]]
G2 = sbm(seed=0, sizes=[N2 // 2, N2 // 2], p=p2)
G3 = sbm(seed=0, sizes=[N3 // 3, N3 // 3, N3 // 3], p=p3)
part_G2 = [G2.nodes[i]["block"] for i in range(N2)]
part_G3 = [G3.nodes[i]["block"] for i in range(N3)]
C2 = networkx.to_numpy_array(G2)
C3 = networkx.to_numpy_array(G3)
# We add node features with given mean - by clusters
# and inversely proportional to clusters' intra-connectivity
F2 = np.zeros((N2, 1))
for i, c in enumerate(part_G2):
F2[i, 0] = np.random.normal(loc=c, scale=0.01)
F3 = np.zeros((N3, 1))
for i, c in enumerate(part_G3):
F3[i, 0] = np.random.normal(loc=2.0 - c, scale=0.01)
# Compute pairwise euclidean distance between node features
M = (F2**2).dot(np.ones((1, N3))) + np.ones((N2, 1)).dot((F3**2).T) - 2 * F2.dot(F3.T)
h2 = np.ones(C2.shape[0]) / C2.shape[0]
h3 = np.ones(C3.shape[0]) / C3.shape[0]
Compute their Fused Gromov-Wasserstein distances
alpha = 0.5
# Conditional Gradient algorithm
print("Conditional Gradient \n")
start_cg = time()
T_cg, log_cg = fused_gromov_wasserstein(
M, C2, C3, h2, h3, "square_loss", alpha=alpha, tol_rel=1e-9, verbose=True, log=True
)
end_cg = time()
time_cg = 1000 * (end_cg - start_cg)
# Proximal Point algorithm with Kullback-Leibler as proximal operator
print("Proximal Point Algorithm \n")
start_ppa = time()
T_ppa, log_ppa = entropic_fused_gromov_wasserstein(
M,
C2,
C3,
h2,
h3,
"square_loss",
alpha=alpha,
epsilon=1.0,
solver="PPA",
tol=1e-9,
log=True,
verbose=True,
warmstart=False,
numItermax=10,
)
end_ppa = time()
time_ppa = 1000 * (end_ppa - start_ppa)
# Projected Gradient algorithm with entropic regularization
print("Projected Gradient Descent \n")
start_pgd = time()
T_pgd, log_pgd = entropic_fused_gromov_wasserstein(
M,
C2,
C3,
h2,
h3,
"square_loss",
alpha=alpha,
epsilon=0.01,
solver="PGD",
tol=1e-9,
log=True,
verbose=True,
warmstart=False,
numItermax=10,
)
end_pgd = time()
time_pgd = 1000 * (end_pgd - start_pgd)
# Alternated Bregman Projected Gradient algorithm with Kullback-Leibler as proximal operator
print("Bregman Alternated Projected Gradient \n")
start_bapg = time()
T_bapg, log_bapg = BAPG_fused_gromov_wasserstein(
M,
C2,
C3,
h2,
h3,
"square_loss",
alpha=alpha,
epsilon=1.0,
tol=1e-9,
marginal_loss=True,
verbose=True,
log=True,
)
end_bapg = time()
time_bapg = 1000 * (end_bapg - start_bapg)
print(
"Fused Gromov-Wasserstein distance estimated with Conditional Gradient solver: "
+ str(log_cg["fgw_dist"])
)
print(
"Fused Gromov-Wasserstein distance estimated with Proximal Point solver: "
+ str(log_ppa["fgw_dist"])
)
print(
"Entropic Fused Gromov-Wasserstein distance estimated with Projected Gradient solver: "
+ str(log_pgd["fgw_dist"])
)
print(
"Fused Gromov-Wasserstein distance estimated with Projected Gradient solver: "
+ str(log_bapg["fgw_dist"])
)
# compute OT sparsity level
T_cg_sparsity = 100 * (T_cg == 0.0).astype(np.float64).sum() / (N2 * N3)
T_ppa_sparsity = 100 * (T_ppa == 0.0).astype(np.float64).sum() / (N2 * N3)
T_pgd_sparsity = 100 * (T_pgd == 0.0).astype(np.float64).sum() / (N2 * N3)
T_bapg_sparsity = 100 * (T_bapg == 0.0).astype(np.float64).sum() / (N2 * N3)
# Methods using Sinkhorn/Bregman projections tend to produce feasibility errors on the
# marginal constraints
err_cg = np.linalg.norm(T_cg.sum(1) - h2) + np.linalg.norm(T_cg.sum(0) - h3)
err_ppa = np.linalg.norm(T_ppa.sum(1) - h2) + np.linalg.norm(T_ppa.sum(0) - h3)
err_pgd = np.linalg.norm(T_pgd.sum(1) - h2) + np.linalg.norm(T_pgd.sum(0) - h3)
err_bapg = np.linalg.norm(T_bapg.sum(1) - h2) + np.linalg.norm(T_bapg.sum(0) - h3)
Conditional Gradient
It. |Loss |Relative loss|Absolute loss
------------------------------------------------
0|8.271184e-01|0.000000e+00|0.000000e+00
1|4.211305e-01|9.640431e-01|4.059879e-01
2|4.024660e-01|4.637523e-02|1.866445e-02
3|3.936346e-01|2.243555e-02|8.831410e-03
4|3.891614e-01|1.149450e-02|4.473216e-03
5|3.854134e-01|9.724554e-03|3.747973e-03
6|3.850574e-01|9.244899e-04|3.559817e-04
7|3.841819e-01|2.279017e-03|8.755571e-04
8|3.819396e-01|5.870728e-03|2.242264e-03
9|3.784264e-01|9.283767e-03|3.513222e-03
10|3.772225e-01|3.191339e-03|1.203845e-03
11|3.764565e-01|2.034974e-03|7.660790e-04
12|3.761179e-01|9.000610e-04|3.385291e-04
13|3.761179e-01|0.000000e+00|0.000000e+00
Proximal Point Algorithm
/home/circleci/project/ot/bregman/_sinkhorn.py:666: UserWarning: Sinkhorn did not converge. You might want to increase the number of iterations `numItermax` or the regularization parameter `reg`.
warnings.warn(
It. |Err
-------------------
0|1.536990e-02|
10|7.472502e-04|
20|6.129779e-04|
30|5.936118e-04|
40|6.334121e-04|
50|6.852583e-04|
60|7.134797e-04|
70|7.177453e-04|
80|7.236970e-04|
90|7.465712e-04|
100|7.858590e-04|
110|8.312306e-04|
120|8.789776e-04|
130|9.493878e-04|
140|1.029873e-03|
150|1.095678e-03|
160|1.177744e-03|
170|1.257392e-03|
180|1.242762e-03|
190|1.125684e-03|
It. |Err
-------------------
200|9.770321e-04|
210|8.368455e-04|
220|7.094853e-04|
230|6.159374e-04|
240|5.564338e-04|
250|4.974174e-04|
260|4.297098e-04|
270|3.639787e-04|
280|3.106686e-04|
290|2.716049e-04|
300|2.433353e-04|
310|2.227167e-04|
320|2.080617e-04|
330|1.980812e-04|
340|1.912468e-04|
350|1.858901e-04|
360|1.805235e-04|
370|1.740559e-04|
380|1.658655e-04|
390|1.557834e-04|
It. |Err
-------------------
400|1.440242e-04|
410|1.310793e-04|
420|1.175881e-04|
/home/circleci/project/ot/backend.py:1304: RuntimeWarning: divide by zero encountered in log
return np.log(a)
430|1.042086e-04|
440|9.151311e-05|
450|7.992882e-05|
460|6.972309e-05|
470|6.101506e-05|
480|5.379844e-05|
490|4.797194e-05|
500|4.337741e-05|
510|3.984020e-05|
520|3.720212e-05|
530|3.534028e-05|
540|3.417109e-05|
550|3.364311e-05|
560|3.372351e-05|
570|3.438312e-05|
580|3.558368e-05|
590|3.726958e-05|
It. |Err
-------------------
600|3.936418e-05|
610|4.176966e-05|
620|4.436877e-05|
630|4.702796e-05|
640|4.960175e-05|
650|5.193888e-05|
660|5.389046e-05|
670|5.531979e-05|
680|5.611295e-05|
690|5.618871e-05|
700|5.550627e-05|
710|5.406954e-05|
720|5.192695e-05|
730|4.916691e-05|
740|4.590932e-05|
750|4.229430e-05|
760|3.846976e-05|
770|3.457933e-05|
780|3.075230e-05|
790|2.709643e-05|
It. |Err
-------------------
800|2.369414e-05|
810|2.060184e-05|
820|1.785186e-05|
830|1.545590e-05|
840|1.340916e-05|
850|1.169442e-05|
860|1.028566e-05|
870|9.150926e-06|
880|8.254840e-06|
890|7.560795e-06|
900|7.033105e-06|
910|6.638947e-06|
920|6.349865e-06|
930|6.142583e-06|
940|5.999120e-06|
950|5.906371e-06|
960|5.855388e-06|
970|5.840590e-06|
980|5.859006e-06|
990|5.909627e-06|
Projected Gradient Descent
It. |Err
-------------------
0|4.981055e-02|
10|1.110756e-01|
20|1.139916e-01|
30|1.158952e-01|
40|1.159648e-01|
50|1.159715e-01|
60|1.159728e-01|
70|1.159732e-01|
80|1.159732e-01|
90|1.159733e-01|
100|1.159733e-01|
110|1.159733e-01|
120|1.159733e-01|
130|1.159733e-01|
140|1.159733e-01|
150|1.159733e-01|
160|1.159733e-01|
170|1.159733e-01|
180|1.159733e-01|
190|1.159733e-01|
It. |Err
-------------------
200|1.159733e-01|
210|1.159733e-01|
220|1.159733e-01|
230|1.159733e-01|
240|1.159733e-01|
250|1.159733e-01|
260|1.159733e-01|
270|1.159733e-01|
280|1.159733e-01|
290|1.159733e-01|
300|1.159733e-01|
310|1.159733e-01|
320|1.159733e-01|
330|1.159733e-01|
340|1.159733e-01|
350|1.159733e-01|
360|1.159733e-01|
370|1.159733e-01|
380|1.159733e-01|
390|1.159733e-01|
It. |Err
-------------------
400|1.159733e-01|
410|1.159733e-01|
420|1.159733e-01|
430|1.159733e-01|
440|1.159733e-01|
450|1.159733e-01|
460|1.159733e-01|
470|1.159733e-01|
480|1.159733e-01|
490|1.159733e-01|
500|1.159733e-01|
510|1.159733e-01|
520|1.159733e-01|
530|1.159733e-01|
540|1.159733e-01|
550|1.159733e-01|
560|1.159733e-01|
570|1.159733e-01|
580|1.159733e-01|
590|1.159733e-01|
It. |Err
-------------------
600|1.159733e-01|
610|1.159733e-01|
620|1.159733e-01|
630|1.159733e-01|
640|1.159733e-01|
650|1.159733e-01|
660|1.159733e-01|
670|1.159733e-01|
680|1.159733e-01|
690|1.159733e-01|
700|1.159733e-01|
710|1.159733e-01|
720|1.159733e-01|
730|1.159733e-01|
740|1.159733e-01|
750|1.159733e-01|
760|1.159733e-01|
770|1.159733e-01|
780|1.159733e-01|
790|1.159733e-01|
It. |Err
-------------------
800|1.159733e-01|
810|1.159733e-01|
820|1.159733e-01|
830|1.159733e-01|
840|1.159733e-01|
850|1.159733e-01|
860|1.159733e-01|
870|1.159733e-01|
880|1.159733e-01|
890|1.159733e-01|
900|1.159733e-01|
910|1.159733e-01|
920|1.159733e-01|
930|1.159733e-01|
940|1.159733e-01|
950|1.159733e-01|
960|1.159733e-01|
970|1.159733e-01|
980|1.159733e-01|
990|1.159733e-01|
Bregman Alternated Projected Gradient
It. |Err
-------------------
0|2.710197e-02|
10|7.722091e-04|
20|1.141907e-03|
30|1.705361e-03|
40|2.217013e-03|
50|2.780133e-03|
60|2.754405e-03|
70|2.618865e-03|
80|2.155365e-03|
90|1.467885e-03|
100|1.234502e-03|
110|1.427166e-03|
120|1.580081e-03|
130|1.480216e-03|
140|1.016301e-03|
150|7.489908e-04|
160|5.527976e-04|
170|3.724086e-04|
180|2.505381e-04|
190|1.890667e-04|
It. |Err
-------------------
200|1.660689e-04|
210|1.596126e-04|
220|1.580415e-04|
230|1.573214e-04|
240|1.554877e-04|
250|1.506710e-04|
260|1.413884e-04|
270|1.273670e-04|
280|1.099326e-04|
290|9.144168e-05|
300|7.415348e-05|
310|5.942604e-05|
320|4.761838e-05|
330|3.844073e-05|
340|3.135983e-05|
350|2.585715e-05|
360|2.152819e-05|
370|1.808727e-05|
380|1.533873e-05|
390|1.314610e-05|
It. |Err
-------------------
400|1.140922e-05|
410|1.004962e-05|
420|9.001810e-06|
430|8.208638e-06|
440|7.619328e-06|
450|7.189212e-06|
460|6.880145e-06|
470|6.660812e-06|
480|6.506527e-06|
490|6.398538e-06|
500|6.323025e-06|
510|6.270041e-06|
520|6.232558e-06|
530|6.205670e-06|
540|6.185991e-06|
550|6.171195e-06|
560|6.159695e-06|
570|6.150412e-06|
580|6.142611e-06|
590|6.135798e-06|
It. |Err
-------------------
600|6.129637e-06|
610|6.123902e-06|
620|6.118440e-06|
630|6.113149e-06|
640|6.107960e-06|
650|6.102825e-06|
660|6.097715e-06|
670|6.092609e-06|
680|6.087492e-06|
690|6.082355e-06|
700|6.077194e-06|
710|6.072003e-06|
720|6.066779e-06|
730|6.061523e-06|
740|6.056231e-06|
750|6.050905e-06|
760|6.045543e-06|
770|6.040145e-06|
780|6.034711e-06|
790|6.029242e-06|
It. |Err
-------------------
800|6.023737e-06|
810|6.018197e-06|
820|6.012621e-06|
830|6.007010e-06|
840|6.001365e-06|
850|5.995684e-06|
860|5.989968e-06|
870|5.984218e-06|
880|5.978434e-06|
890|5.972615e-06|
900|5.966762e-06|
910|5.960875e-06|
920|5.954955e-06|
930|5.949001e-06|
940|5.943013e-06|
950|5.936992e-06|
960|5.930938e-06|
970|5.924851e-06|
980|5.918731e-06|
990|5.912579e-06|
Fused Gromov-Wasserstein distance estimated with Conditional Gradient solver: 0.3761179313933098
Fused Gromov-Wasserstein distance estimated with Proximal Point solver: 0.3671471715862438
Entropic Fused Gromov-Wasserstein distance estimated with Projected Gradient solver: 0.21736592892258025
Fused Gromov-Wasserstein distance estimated with Projected Gradient solver: 0.2576635020911173
Visualization of the Fused Gromov-Wasserstein matchings
We color nodes of the graph on the right - then project its node colors based on the optimal transport plan from the FGW matchings We adjust the intensity of links across domains proportionaly to the mass sent, adding a minimal intensity of 0.1 if mass sent is not zero. For each matching, all node sizes are proportionnal to their mass computed from marginals of the OT plan to illustrate potential feasibility errors. NB: colors refer to clusters - not to node features
# Add weights on the edges for visualization later on
weight_intra_G2 = 5
weight_inter_G2 = 0.5
weight_intra_G3 = 1.0
weight_inter_G3 = 1.5
weightedG2 = networkx.Graph()
part_G2 = [G2.nodes[i]["block"] for i in range(N2)]
for node in G2.nodes():
weightedG2.add_node(node)
for i, j in G2.edges():
if part_G2[i] == part_G2[j]:
weightedG2.add_edge(i, j, weight=weight_intra_G2)
else:
weightedG2.add_edge(i, j, weight=weight_inter_G2)
weightedG3 = networkx.Graph()
part_G3 = [G3.nodes[i]["block"] for i in range(N3)]
for node in G3.nodes():
weightedG3.add_node(node)
for i, j in G3.edges():
if part_G3[i] == part_G3[j]:
weightedG3.add_edge(i, j, weight=weight_intra_G3)
else:
weightedG3.add_edge(i, j, weight=weight_inter_G3)
def draw_graph(
G,
C,
nodes_color_part,
Gweights=None,
pos=None,
edge_color="black",
node_size=None,
shiftx=0,
seed=0,
):
if pos is None:
pos = networkx.spring_layout(G, scale=1.0, seed=seed)
if shiftx != 0:
for k, v in pos.items():
v[0] = v[0] + shiftx
alpha_edge = 0.7
width_edge = 1.8
if Gweights is None:
networkx.draw_networkx_edges(
G, pos, width=width_edge, alpha=alpha_edge, edge_color=edge_color
)
else:
# We make more visible connections between activated nodes
n = len(Gweights)
edgelist_activated = []
edgelist_deactivated = []
for i in range(n):
for j in range(n):
if Gweights[i] * Gweights[j] * C[i, j] > 0:
edgelist_activated.append((i, j))
elif C[i, j] > 0:
edgelist_deactivated.append((i, j))
networkx.draw_networkx_edges(
G,
pos,
edgelist=edgelist_activated,
width=width_edge,
alpha=alpha_edge,
edge_color=edge_color,
)
networkx.draw_networkx_edges(
G,
pos,
edgelist=edgelist_deactivated,
width=width_edge,
alpha=0.1,
edge_color=edge_color,
)
if Gweights is None:
for node, node_color in enumerate(nodes_color_part):
networkx.draw_networkx_nodes(
G,
pos,
nodelist=[node],
node_size=node_size,
alpha=1,
node_color=node_color,
)
else:
scaled_Gweights = Gweights / (0.5 * Gweights.max())
nodes_size = node_size * scaled_Gweights
for node, node_color in enumerate(nodes_color_part):
networkx.draw_networkx_nodes(
G,
pos,
nodelist=[node],
node_size=nodes_size[node],
alpha=1,
node_color=node_color,
)
return pos
def draw_transp_colored_GW(
G1,
C1,
G2,
C2,
part_G1,
p1,
p2,
T,
pos1=None,
pos2=None,
shiftx=4,
switchx=False,
node_size=70,
seed_G1=0,
seed_G2=0,
):
starting_color = 0
# get graphs partition and their coloring
part1 = part_G1.copy()
unique_colors = ["C%s" % (starting_color + i) for i in np.unique(part1)]
nodes_color_part1 = []
for cluster in part1:
nodes_color_part1.append(unique_colors[cluster])
nodes_color_part2 = []
# T: getting colors assignment from argmin of columns
for i in range(len(G2.nodes())):
j = np.argmax(T[:, i])
nodes_color_part2.append(nodes_color_part1[j])
pos1 = draw_graph(
G1,
C1,
nodes_color_part1,
Gweights=p1,
pos=pos1,
node_size=node_size,
shiftx=0,
seed=seed_G1,
)
pos2 = draw_graph(
G2,
C2,
nodes_color_part2,
Gweights=p2,
pos=pos2,
node_size=node_size,
shiftx=shiftx,
seed=seed_G2,
)
for k1, v1 in pos1.items():
max_Tk1 = np.max(T[k1, :])
for k2, v2 in pos2.items():
if T[k1, k2] > 0:
pl.plot(
[pos1[k1][0], pos2[k2][0]],
[pos1[k1][1], pos2[k2][1]],
"-",
lw=0.7,
alpha=min(T[k1, k2] / max_Tk1 + 0.1, 1.0),
color=nodes_color_part1[k1],
)
return pos1, pos2
node_size = 40
fontsize = 13
seed_G2 = 0
seed_G3 = 4
pl.figure(2, figsize=(15, 3.5))
pl.clf()
pl.subplot(141)
pl.axis("off")
pl.title(
"(CG) FGW=%s\n \n OT sparsity = %s \n marg. error = %s \n runtime = %s"
% (
np.round(log_cg["fgw_dist"], 3),
str(np.round(T_cg_sparsity, 2)) + " %",
np.round(err_cg, 4),
str(np.round(time_cg, 2)) + " ms",
),
fontsize=fontsize,
)
pos1, pos2 = draw_transp_colored_GW(
weightedG2,
C2,
weightedG3,
C3,
part_G2,
p1=T_cg.sum(1),
p2=T_cg.sum(0),
T=T_cg,
shiftx=1.5,
node_size=node_size,
seed_G1=seed_G2,
seed_G2=seed_G3,
)
pl.subplot(142)
pl.axis("off")
pl.title(
"(PPA) FGW=%s\n \n OT sparsity = %s \n marg. error = %s \n runtime = %s"
% (
np.round(log_ppa["fgw_dist"], 3),
str(np.round(T_ppa_sparsity, 2)) + " %",
np.round(err_ppa, 4),
str(np.round(time_ppa, 2)) + " ms",
),
fontsize=fontsize,
)
pos1, pos2 = draw_transp_colored_GW(
weightedG2,
C2,
weightedG3,
C3,
part_G2,
p1=T_ppa.sum(1),
p2=T_ppa.sum(0),
T=T_ppa,
pos1=pos1,
pos2=pos2,
shiftx=0.0,
node_size=node_size,
seed_G1=0,
seed_G2=0,
)
pl.subplot(143)
pl.axis("off")
pl.title(
"(PGD) Entropic FGW=%s\n \n OT sparsity = %s \n marg. error = %s \n runtime = %s"
% (
np.round(log_pgd["fgw_dist"], 3),
str(np.round(T_pgd_sparsity, 2)) + " %",
np.round(err_pgd, 4),
str(np.round(time_pgd, 2)) + " ms",
),
fontsize=fontsize,
)
pos1, pos2 = draw_transp_colored_GW(
weightedG2,
C2,
weightedG3,
C3,
part_G2,
p1=T_pgd.sum(1),
p2=T_pgd.sum(0),
T=T_pgd,
pos1=pos1,
pos2=pos2,
shiftx=0.0,
node_size=node_size,
seed_G1=0,
seed_G2=0,
)
pl.subplot(144)
pl.axis("off")
pl.title(
"(BAPG) FGW=%s\n \n OT sparsity = %s \n marg. error = %s \n runtime = %s"
% (
np.round(log_bapg["fgw_dist"], 3),
str(np.round(T_bapg_sparsity, 2)) + " %",
np.round(err_bapg, 4),
str(np.round(time_bapg, 2)) + " ms",
),
fontsize=fontsize,
)
pos1, pos2 = draw_transp_colored_GW(
weightedG2,
C2,
weightedG3,
C3,
part_G2,
p1=T_bapg.sum(1),
p2=T_bapg.sum(0),
T=T_bapg,
pos1=pos1,
pos2=pos2,
shiftx=0.0,
node_size=node_size,
seed_G1=0,
seed_G2=0,
)
pl.tight_layout()
pl.show()
Total running time of the script: (0 minutes 2.630 seconds)